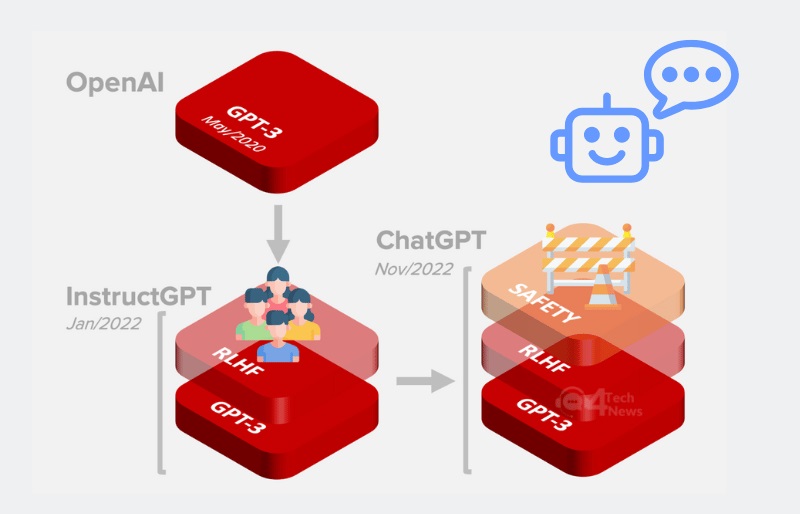
Để có được sự thành công như ngày hôm nay, các nhà khoa học của OpenAI đã áp dụng rất nhiều công nghệ, kỹ thuật hiện đại nhằm huấn luyện và đào tạo Chat GPT. Theo đó, RLHF là một công nghệ mới được ứng dụng để tạo ra các chatbot có khả năng giao tiếp trơn tru, mượt mà như con người. Vậy RLHF là gì? Cách RLHF hoạt động như thế nào? DNS sẽ giải đáp chi tiết mọi thắc mắc và đưa ra những thông tin hữu ích đến bạn trong bài viết ngày hôm nay.
RLHF là gì?
RLHF – Reinforce Learning from Human Feedbacks có nghĩa Tiếng Việt là Học tăng cường từ phản hồi của con người. Đây là một ý tưởng hay bắt nguồn từ việc cần phải có sự cải tiến nhanh chóng trong quá trình đánh giá chất lượng văn bản của các dòng AI tạo nội dung.
Theo đó, trước khi kỹ thuật RLHF ra đời, các dòng AI tạo nội dung như dòng dịch máy được đánh giá chất lượng văn bản bằng cách sử dụng loss function. Không chỉ vậy, họ cũng cải tiến khả năng đánh giá với các kỹ thuật mới khác như BLEU hay ROUGE.
Tuy nhiên, các dòng AI tạo nội dung thường được coi là các mô hình ngôn ngữ. Trong khi đó, ngôn ngữ vốn đa dạng và phức tạp. Chính vì thế, các nhà khoa học đã nảy ra ý tưởng đó là tại sao không sử dụng chính phản hồi của người dùng để đánh giá nội dung do máy tạo ra cũng như việc sử dụng những phản hồi đó để tối ưu hóa mô hình.
Cách hoạt động của công nghệ RLHF
RLHF là một kỹ thuật mới trong giới công nghệ hiện nay nên khá khó đối với những ai không quá hiểu sâu về công nghệ. Dù vậy, bạn vẫn có được cái nhìn tổng quan về cách kỹ thuật RLHF hoạt động với 3 bước chính bao gồm:
- Sử dụng pre-trained Language Model (LM)
- Thu thập dữ liệu và huấn luyện Reward Model
- Fine-tuning LM bằng Reward Model vừa được huấn luyện
Phân tích chi tiết từng bước hoạt động của công nghệ RLHF như sau:
Pretraining Language Models
Đây là bước huấn luyện Language Models bằng cách sử dụng những data, kiến trúc, label,…có sẵn cho từng tác vụ. Về cơ bản thì ở bước này vẫn sẽ huấn luyện một LM như thường.
Tùy từng mục tiêu mà sẽ lựa chọn mô hình phù hợp. Ví dụ: Đối với Chat GPT, họ sẽ sử dụng một phần của GPT -3 để fine-tune lại nhiệm vụ sản xuất nội dung văn bản.
Nói dễ hiểu nhất thì trong công đoạn này, chỉ cần chú ý tùy chỉnh model sao cho ổn là được. Vai trò chính của mô hình này sẽ là để sản sinh văn bản. Và để giám sát thì họ sử dụng đến quy trình học có giám sát, mang tên Supervised Fine-tuned (SFT).
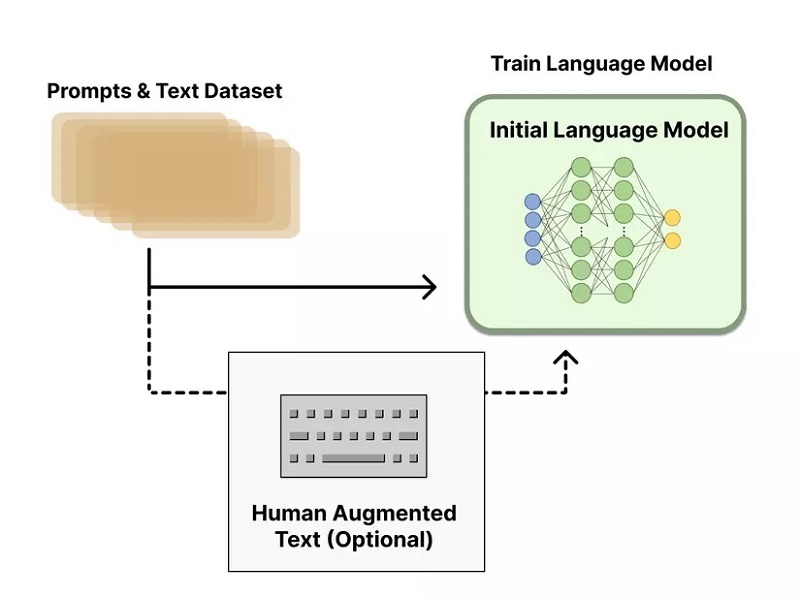
Thu thập dữ liệu và huấn luyện Reward Model
Tạo ra một Reward Model (RM), hay còn được hiểu là preference model được coi là khởi đầu cho các nghiên cứu chuyên sâu về kỹ thuật RLHF. Công đoạn này đã giúp RLHF trở nên nổi bật so với các kỹ thuật đánh giá văn bản được sử dụng trước đây. Chính vì thế, mục tiêu mà các nhà nghiên cứu luôn hướng đến đó là tối ưu reward function trong bài toán RL.
Vậy quy trình huấn luyện Reward Model diễn ra như thế nào? Rất đơn giản, đầu tiên cần thu thập data bằng cách sử dụng nhiều LM khác nhau (Pre-traned model hoặc model train-from-scratch). Tiếp đó, sử dụng những model vừa thu thập được để sinh hàng loạt văn bản với cùng một Prompt.
Tham khảo thêm: Prompt trong Chat GPT là gì?
Khi số lượng văn bản được sinh ra đã đạt mức tương đối, lúc này con người sẽ can thiệp vào quy trình bằng cách đánh giá các văn bản này theo thứ tự từ tốt nhất cho đến kém chất lượng nhất. Sau đó, số data vừa được đánh giá sẽ được sử dụng để huấn luyện cho RM, có nghĩa chúng ta sẽ phải dùng model để tạo data cho một model khác và quyền đánh giá (Labelling) sẽ do con người thực hiện.

Nguyên liệu cho RM
Những thành phần làm nguyên liệu cho RM đó là:
- Prompt x: Chỉ dẫn cho pre-trained model sinh văn bản. Câu lệnh này được lấy từ 1 database D lớn hơn. Từ prompt ta sẽ có 2 sample là j và k được sinh ra.
- yi (với i∈ {0, 1}): Ground truth label của RM, dùng để con người đánh giá 2 sample j và k.
Khi đó, hàm loss cho mô hình Reward Model sẽ có dạng:
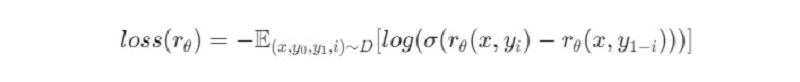
Fine-tuning RL model với RM model
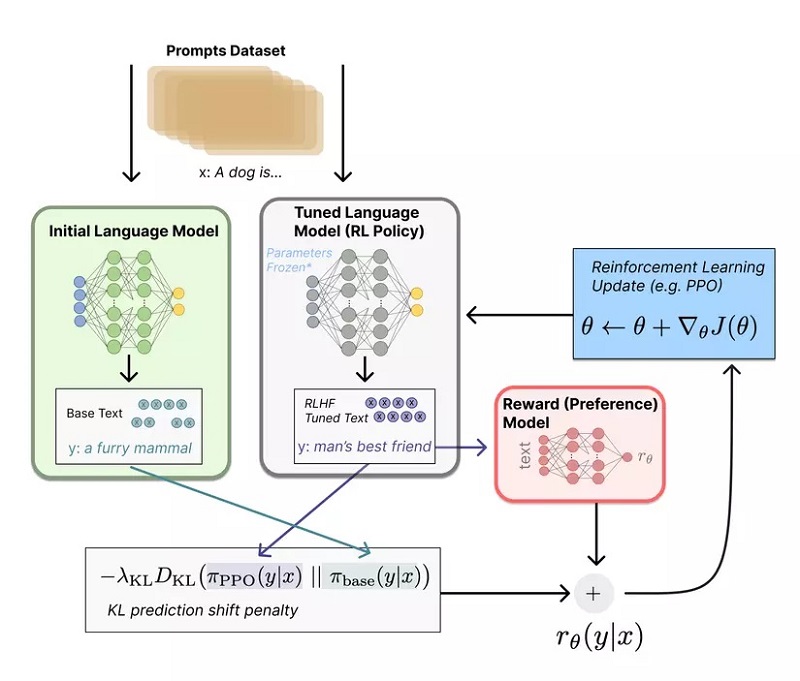
Sau khi huấn luyện xong Reward thì chúng ta tiến đến bước huấn luyện RL. Tại đây, sẽ cần đến 2 LM: 1 cái từ bước a và 1 cái khác. Theo đó, cái LM “khác” có đặc điểm đó là sử dụng thuật toán tối ưu policy mang tên Proximal Policy Optimization (PPO). Chính vì vậy, có thể gọi LM thứ 2 là PPO Model và quá trình fine-tuning RL model được diễn ra như sau:
- Prompt mới được đưa vào làm input cho cả quá trình
- Tạo Policy πbase (Là output của LM hoặc phân phối xác suất của các từ vựng của output) bằng cách sử dụng LM ở phần đầu tiên từ những input prompt, rồi từ đó sinh ra văn bản.
- Trong cùng lúc, PPO Model cũng sẽ sản sinh ra văn bản từ prompt mới.
- Sau khi sản sinh ra văn bản thì RM đã được huấn luyện sẽ đánh giá văn bản mới để cập nhật Reward Function do PPO Model. Hàm cập nhật cho PPO sẽ có dạng như sau:
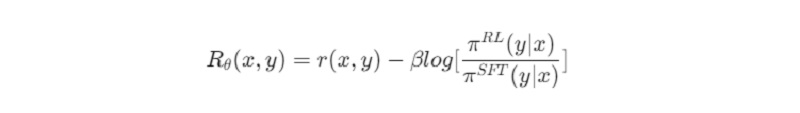
Trong đó r(x,y) sẽ là output của RM, β là một hyperparameter, π RL (y∣x) là policy sẽ được tối ưu bởi PPO và π SFT (y∣x). Đây chính là policy từ model SFT.
Việc sử dụng KL Divergence với mục đích đảm bảo các output được sinh ra không khác quá nhiều so với những gì RM được huấn luyện. Quá trình tối ưu sẽ được lặp đi lặp lại và đây cũng chính là cách mà Chat GPT hoạt động.
Cách Chat GPT hoạt động
Cách hoạt động của công nghệ Chat GPT được diễn ra như những gì chúng tôi đề cập cho các bạn ở trên. Bởi công nghệ này hoạt động dựa vào kỹ thuật RLHF. Do đó, chatbot sẽ có khả năng nói chuyện giống như con người.
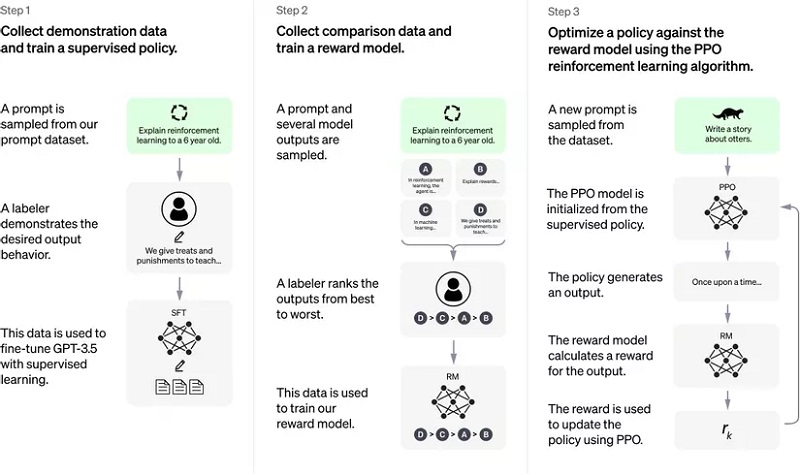
Có thể tóm gọn quy trình hoạt động của Chat GPT thành các bước như sau:
- Thực hiện fine-tuning với một LLM (GPT -3) nhằm tạo ra GPT -3.5, là một model supervised-learning có sẵn từ bộ data.
- Khi đã có hàng loạt sample được tạo ra, con người sẽ đánh giá và chấm điểm cho từng sample nhằm có được data huấn luyện RM.
- Bước cuối là chúng ta đã có SFT model và RM. Hãy thực hiện tối ưu Policy bằng thuật toán PPO để output thật nhất có thể.
Những lỗ hổng của cơ chế hoạt động RLHF
OpenAI đã đầu tư rất mạnh vào Chat GPT để làm cho chúng trở nên an toàn hơn. Chiến lược đào tạo chính của công cụ này đó là sử dụng phương pháp RLHF.
Và qua những thông tin được tìm hiểu ở trên, chúng tôi có thể đúc kết lại đó là các nhà phát triển sẽ đặt ra thật nhiều câu hỏi cho mô hình rồi trừng phạt những câu trả lời sai và thưởng cho những câu trả lời đúng. Từ đó, kiểm soát chất lượng câu trả lời của Chat GPT một cách hiệu quả nhất.
Dù vậy, cơ chế hoạt động của RLHF vẫn còn tồn tại một số lỗ hổng mà Scott Alexander – Một người đam mê AI nổi tiếng, đã chỉ ra đó là:
- RLHF doesn’t work well – RLHF không hoạt động hiệu quả
- Sometimes when it does work, it’s bad
- At some point, AIs can just skip it – Ở một vài thời điểm, AI có thể bỏ qua RLHF
Lý do Scott nói RLHF hoạt động hiệu quả không thường xuyên và không đáng tin cậy là vì các chiến lược RLHF yêu cầu liên kết mô hình AI với các yếu tố do người chú thích cung cấp nhằm thưởng hoặc phạt mô hình. Dù OpenAI vẫn chưa công bố cụ thể thông số kỹ thuật nhưng người ta cũng đoán ra được rằng các nhà phát triển chú trọng đến 3 mục tiêu chính đó là:
- Cung cấp câu trả lời hữu ích, rõ ràng
- Nói đúng sự thật
- Không nói lời xúc phạm
Vậy bạn có nghĩ đến trường hợp cả 3 mục tiêu đều mâu thuẫn với nhau hay chưa?
Nếu Chat GPT không biết câu trả lời thực sự là gì thì khi mục tiêu 1 mâu thuẫn với mục tiêu 2, mục tiêu 1 sẽ được ưu tiên. Chat GPT sẽ tự tạo ra câu trả lời và làm cho người đọc cảm thấy câu trả lời đó hữu ích.
Mặc dù mục tiêu 2 xung đột với mục tiêu 3 nhưng Chat GPT sẽ cố gắng đưa ra câu trả lời chung chung nhất có thể và không gây xúc phạm đến bất kỳ đối tượng nào.
Trong quá trình đào tạo thực tế, OpenAI đã phải dán nhãn cho hơn 6.000 mẫu RLHF nhằm đạt được hiệu quả đáng kinh ngạc. Kỹ thuật RLHF sẽ rất hữu ích chỉ khi chúng được sử dụng cẩn thận. Nếu sử dụng kỹ thuật này mà không suy nghĩ, khả năng cao chúng sẽ đẩy Chatbot đi vòng quanh những mẫu lỗi.
Nói tóm lại, thách thức trong việc kiểm soát các chương trình trí tuệ nhân tạo như chatbot là rất lớn. Trong đó, việc đảm bảo các mục tiêu chính của chương trình như cung cấp câu trả lời hữu ích, nói đúng sự thật và không xúc phạm có thể mâu thuẫn với nhau, gây khó khăn cho việc lập trình và kiểm soát chương trình. RLHF là một phương pháp để giúp kiểm soát chương trình, nhưng cần được sử dụng cẩn thận. Việc đào tạo các chương trình trí tuệ nhân tạo cũng đòi hỏi sự dán nhãn và giám sát của con người.
Bạn có thể tham khảo thêm thông tin TẠI ĐÂY.
Như vậy, toàn bộ thông tin trên đã giúp bạn giải đáp được RLHF là gì và phương pháp này được ứng dụng trong Chat GPT như thế nào. Có thể thấy rằng, kỹ thuật học từ Human Feedbacks đã mang đến những điều bất ngờ trong giới công nghệ nhưng chúng vẫn còn tồn tại một vài lỗ hổng chưa được khắc phục hoàn toàn. Nếu bạn cảm thấy những thông tin DNS chia sẻ hữu ích thì hãy quay trở lại và đọc thêm nhiều bài viết khác nhé.
Tài liệu tham khảo:
Understanding Reinforcement Learning from Human Feedback (RLHF): Part 1
Illustrating Reinforcement Learning from Human Feedback (RLHF)
Pingback: Chat GPT là gì? Tổng hợp thông tin quan trọng về Chat GPT